? 优质资源分享 ?
| 学习路线指引(点击解锁) | 知识定位 | 人群定位 |
|---|---|---|
| ? Python实战微信订餐小程序 ? | 进阶级 | 本课程是python flask+微信小程序的完美结合,从项目搭建到腾讯云部署上线,打造一个全栈订餐系统。 |
| ?Python量化交易实战? | 入门级 | 手把手带你打造一个易扩展、更安全、效率更高的量化交易系统 |
目录* 1、正则表达式说明
1、正则表达式说明
正则表达式和通配符的区别
- 正则表达式用来在文件中匹配符合条件的字符串。
- 通配符用来匹配符合条件的文件名。
在Shell中,使用在文件当中搜索字符串的命令,如grep,awk,sed等命令(文本操作三剑客),可以支持正则表达式。
而在系统当中搜索文件的命令,如ls,find,cp这些命令不支持正则表达式,所以只能使用通配符来进行匹配了。
- 在Shell中只要是匹配字符串,都适用于正则匹配。
- 正则表达式匹配的是以一行为单位进行包含匹配的,匹配上就显示输出该行文本,否则不显示。
2、基础正则表达式
| 元字符 | 作用 |
|---|---|
* |
匹配前一个字符匹配0次或任意多次。 |
. |
匹配除了换行符外任意一个字符。 |
^ |
匹配行首。例如:^hello会匹配以hello开头的行。 |
$ |
匹配行尾。例如:hello$会匹配以hello结尾的行。 |
[] |
匹配中括号中指定的任意一个字符,只匹配一个字符。例如:[aoeiu]匹配意一个元音字母,[0-9]匹配任意一位数字,[a-z][0-9]匹配小写字和一位数字构成的两位字符。 |
[^] |
匹配除中括号的字符以外的任意一个字符。例如:[^0-9]匹配任意一位非数字字符,[^a-z]表示任意一位非小写字母。 |
\ |
转义符。用于取消将特殊符号的含义取消。 |
\{n\} |
表示其前面的字符恰好出现n次。例如:[0-9]\{4\}匹配4位数字,[1][3-8][0-9]\{9\}匹配手机号码。 |
\{n,\} |
表示其前面的字符出现不小于n次。例如:[0-9]\{2,\}表示两位及以上的数字。 |
\{n,m\} |
表示其前面的字符至少出现n次,最多出现m次。例如:[a-z]\{6,8\}匹配6到8位的小写字母。 |
注意:Shell语言不是一个标准的完整语言,在其他语言中的正则表达式中,是不分基础正则和扩展正则的。而Shell认为你不需要拿正则写太过复杂的字符串筛选格式,所以Shell建议把正则表达式分成基础正则和扩展正则两种。
3、练习
(1)准备工作
创建一个测试文档test.txt
shell
Seven times have I despised my soul:
——Kahlil Gibran
The first time when I saw her being meek that she might attain height.
The second time when I saw her limping before the crippled.
The third time when she was given to choose between the hard and the easy, and she chose the easy.
The fourth time when she committed a wrong, and comforted herself that others also commit wrong.
The fifth time when she forbore for weakness, and attributed her patience to strength.
The sixth time when she despised the ugliness of a face, and knew not that it was one of her own masks.
And the seventh time when she sang a song of praise, and deemed it a virtue.(内容为纪伯伦——我曾七次鄙视自己的灵魂)
还有,为了方便查看,我们可以给grep命令配置带有颜色输出,也就是给grep命令定义一个别名。
在当前用户家目录中的~/.bashrc文件中配置grep命令别名:
shell
# 我们当前的用户是root用户
# 执行命令
[root@localhost ~]# vim /root/.bashrc
# 添加内容
alias grep='grep --color=auto'
# 或者
# 针对所有用户
# echo "alias grep='grep --color=auto'" >>/etc/bashrc
# 针对单个用户
# echo "alias grep='grep --color=auto'" >>~/.bashrc
这样在grep命令执行后的标准输出中,就会将文件中匹配的内容标识彩色。
注意:如果在XShell终端修改的~/.bashrc配置文件,需要关闭当前远程窗口,重新打开就可以实现了。
(2)*练习
我们执行如下命令,进行*匹配练习。
shell
[root@localhost tmp]# grep "k*" test.txt结果如下:

说明:(重点)
任何字母加上*,或者说任何符号加上*,都没有任何含义,这样会匹配所有内容,包括空白行。
因为*的作用是重复前一个字符0次或任意多次。
所以在Shell中的正则中,任何符号加上*是没有任何含义的,所有的内容都会被匹配出来。
如果你需要匹配至少包含一个k字母的行,就需要这样写"kk*",代表匹配至少包含有一个K的行,也可以有多个k。(这行字符串一定要有一个k,但是后面有没有k都可以。)
如下图:

我们可以看到,没有k的行,和空行都被过滤掉了。
如果我们需要匹配至少两个连续的ss字符,需要执行如下命令:
grep "sss*" test.txt

以此类推。
注意:
正则是包含匹配,只要含有就会列出,所以单独搜索一个k,执行grep "k" test.txt 命令,也能获得和上面一样的匹配结果。如下图:

换句话说,上面这两种写法是一个意思,都是搜索含有k字母的行,一行中有一个k字母就可以,有无数个k字母也可以,都会被匹配出来。
限位(制)符:
如果是上面描述的这种简单匹配需求,使用哪种方式都可以。
但是有限位(制)符出现的匹配情况,带*的方式,处理匹配的情况更丰富。
如下面一段文本:
highlighter- mipsasm
Stay hungry, stay foolish. ——Steve Jobs
求知若饥,虚心若愚。——乔布斯
Stay hungry, stay folish. ——Steve Jobs
Stay hungry, stay fooolish. ——Steve Jobs
Stay hungry, stay foooolish. ——Steve Jobs
Stay hungry, stay fooooolish. ——Steve Jobs
我们可以看到上端文本中foolish中有不同数量的o。(自己随意错写的)
如果我的需求是搜索foolish单词中有三个以上数量o的行,这个时候就需要限位(制)符了,
其中foolish单词中的f和l就是限位(制)符的用法。
执行命令如下:
shell
[root@192 tmp]# grep "foooo*lish" test2.txt结果如下:

说明:其中前三个o代表固定有三个连续的o字母出现,最后一个o*代表可以匹配0次到任意多次个o字母。
在这种需要有限位(制)符情况下的匹配,加上*就非常好处理了。
(3).练习
正则表达式.匹配除了换行符外任意一个字符。
举个例子:
文本test2.txt内容如下:
highlighter- gauss
abc adapt 适应 xyz
abc adopt 采用 xyz
xyz adept 内行 abc
xyz floor 地板 abc
xyz flour 面粉 abc- 匹配在
d和t这两个字母之间一定有两个字符的单词。
执行命令:grep "d..t" test2.txt
- 结合
*使用。
执行命令:grep "z.*a" test2.txt
配置的是a和z两个字母之间有任何字符的内容。 - 如果想匹配所有内容,标准写法为
.*。
执行命令:grep ".*" test2.txt
(4)^和$练习
正则表达式^匹配行首,$匹配行尾。
文本test2.txt内容如下:
highlighter- gauss
abc adapt 适应 xyz
abc adopt 采用 xyz
xyz adept 内行 abc.
xyz floor 地板 abc
xyz flour 面粉 abc^代表匹配行首,比如^a会匹配以小写a开头的行。
执行命令:grep "^a" test2.txt
$代表匹配行尾,如果c$会匹配以小写c结尾的行。
执行命令:grep "c$" test2.txt
^$则会匹配空白行。
执行命令:grep "^$" test2.txt
在实际的应用中,我们很少这样使用,一般使用grep命令的-v选项进行取反,来过滤掉空白行。(标准方式)
执行命令:grep -v "^$" test2.txt
$结合.使用。
如果我们要匹配以句号.结果的行,那是否用.$来进行匹配呢?
我们先来执行一下命令:rep ".$" test2.txt
我们看到是匹配了任意字符结尾的行,只是过滤的空白行。
也就是说正则表达式.$中的.是正则符号的意思,表示匹配除了换行符外任意一个字符。
如果我们想匹配以句号.结束的行,我们需要在.前加入转义符,把.变成普通字符串,如:\.$。
执行命令:grep "\.$" test2.txt
说明:
在使用
^匹配行首,$匹配行尾的时候,如果使用的是特殊符号开头或者结尾,我们需要使用转义符进行转义,再进行匹配。
(5)[]练习
正则表达式[]匹配中括号中指定的任意一个字符,只匹配一个字符。(注意只能匹配一个字符。)
比如[abc]要么会匹配一个a字符,要么会匹配一个b字符,或者要么会匹配一个c字符。
文本test.txt内容如下:
highlighter- vim
abc adapt 适应 abc
ABC adopt 采用 xyz
abc adept 内行 XYZ
123 floor 地板 ABC
123 flour 面粉 123- 配置
adapt、adopt、adept这三个近似的单词。
执行命令:grep "ad[ae]pt" test2.txt
可以看出[]比.的匹配范围更精准,请根据实际情况,按需使用。 [0-9]会匹配任意一个数字。
执行命令:grep "[0-9]" test2.txt
[A-Z]会匹配一个大写字母。
执行命令:grep "[A-Z]" test2.txt
^[a-z]代表匹配用小写字母开头的行。
执行命令:grep "^[a-z]" test2.txt
(6)[^]练习
正则表达式[^]匹配除中括号的字符以外的任意一个字符。
就相当于在[]中的内容进行取反。
文本test.txt内容如下:
highlighter- vim
abc adapt 适应 abc
ABC adopt 采用 xyz
abc adept 内行 XYZ
123 floor 地板 ABC
123 flour 面粉 123- 不匹配数字。
执行命令:grep "[^0-9]" test2.txt
- 不匹配以数字开头的行。
执行命令:grep "^[^0-9]" test2.txt
- 不匹配英文。
执行命令:rep "[^a-zA-Z]" test2.txt
- 匹配不以英文结尾的行。
执行命令:rep "[^a-zA-Z]$" test2.txt
(7)\{n\}练习
\{n\}表示其前面的字符恰好出现n次。
提示:\{n\}中的\表示转义符,下面同理。
如下面一段文本:
highlighter- mipsasm
Stay hungry, stay foolish. ——Steve Jobs
求知若饥,虚心若愚。——乔布斯
Stay hungry, stay folish. ——Steve Jobs
Stay hungry, stay fooolish. ——Steve Jobs
Stay hungry, stay foooolish. ——Steve Jobs
Stay hungry, stay fooooolish. ——Steve Jobs
- 匹配包含三个连续的
o。
执行命令:grep "o\{3\}" test2.txt
可以看到有三个连续的o,或者包含三个连续o,都会被匹配到。
那与直接正则匹配三个o有什么区别?
执行命令:grep "ooo" test2.txt
原因:
如果是想匹配一个重复的字母,直接匹配字母的方式更为方便。
而如果我想要匹配重复任意字母或者数字,则\{n\}方式更为便捷。
看下面练习。 - 匹配三个连续的数字。
文本内容如下:highlighter- maximaabc adapt 适应 abc 12a adopt 采用 12345
abc adept 内行 XYZ
1b3 floor 地板 7788999
123 flour 面粉 123
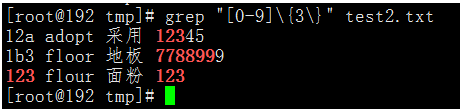
执行命令:grep "[0-9]\{3\}" test2.txt
[](https://img2022.cnblogs.com/blog/909968/202206/909968-20220601110635078-2067500140.png)
我们可以看到,有三个连续的数字,或者包含有三个连续数字的文本,都被匹配到了。
如果我们要是不用\{n\}的方式进行正则匹配的话,如下:
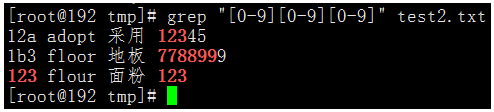
执行命令:grep "[0-9][0-9][0-9]" test2.txt
[](https://img2022.cnblogs.com/blog/909968/202206/909968-20220601110948228-424402617.png)
我们可以看到上边的命令就会麻烦很多,如果要是匹配10个连续的数字,那命令就非常的冗余了。
字母也是同理的。
* 只匹配三个连续的数字
虽然上面的12345和7788999是包含三个连续的数字,所以也是可以列出的。
可是这样不能体现出来[0-9]\{3\}只能匹配三个连续的数字,而不是匹配四个连续的数字。
那么正则中就应该加入限位(制)符(可以是前后有标识的字符或者是行尾行首等进行限位),如下:
执行命令,限制行首:grep "^[0-9]\{3\}" test2.txt
[](https://img2022.cnblogs.com/blog/909968/202206/909968-20220601111017026-1463369175.png)
或者限制行尾,注意前边要多加一个空格限位,才能符合该需求。
执行命令:grep " [0-9]\{3\}$" test2.txt
[](https://img2022.cnblogs.com/blog/909968/202206/909968-20220601111102709-150408676.png)
* 用上面一段文本,练习匹配只包含三个o的文本。
执行命令:grep "fo\{3\}l" test2.txt
[](https://img2022.cnblogs.com/blog/909968/202206/909968-20220601111125043-1334967480.png)
说明:f和l就是限位(制)符。
>
> 注意:
>
>
> \{n\}匹配的方式一般不会用于匹配字母,多用于匹配数字,如电话号码。
>
>
> 还要再重复一遍,正则表达式是包含匹配,多注意限位(制)符的使用。
>
>
>
### (8)\{n,\}练习
\{n,\}表示其前面的字符出现不小于n次。
如下面一段文本:
highlighter- mipsasmStay hungry, stay foolish. ——Steve Jobs
求知若饥,虚心若愚。——乔布斯
Stay hungry, stay folish. ——Steve Jobs
Stay hungry, stay fooolish. ——Steve Jobs
Stay hungry, stay foooolish. ——Steve Jobs
Stay hungry, stay fooooolish. ——Steve Jobs
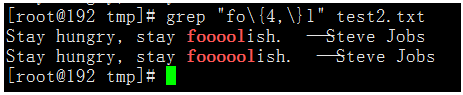
比如fo\{4,\}l这个正则就会匹配用f开头,l结尾,中间最少有4个o的字符串。
执行命令:grep "fo\{4,\}l" test2.txt
[](https://img2022.cnblogs.com/blog/909968/202206/909968-20220601111204553-1639312734.png)
正则表达是fo\{4,\}l与ooooo*的区别同上边(7)\{n\}同理。
练习:匹配至少连续5个字数的文本。
highlighter- maximaabc adapt 适应 abc
12a adopt 采用 12345
abc adept 内行 XYZ
1b3 floor 地板 7788999
123 flour 面粉 123
执行命令:grep "[0-9]\{4,\}" test2.txt
[](https://img2022.cnblogs.com/blog/909968/202206/909968-20220601111220717-1179533210.png)
### (9)\{n,m\}练习
\{n,m\}匹配其前面的字符至少出现n次,最多出现m次。
下面一段文本:
highlighter- mipsasmStay hungry, stay foolish. ——Steve Jobs
求知若饥,虚心若愚。——乔布斯
Stay hungry, stay folish. ——Steve Jobs
Stay hungry, stay fooolish. ——Steve Jobs
Stay hungry, stay foooolish. ——Steve Jobs
Stay hungry, stay fooooolish. ——Steve Jobs
Stay hungry, stay foooooolish. ——Steve Jobs
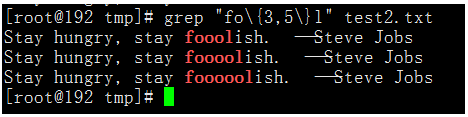
匹配在字母f和字母l之间有最少3个o,最多5个o。
执行命令:grep "fo\{3,5\}l" test2.txt
[](https://img2022.cnblogs.com/blog/909968/202206/909968-20220601111234774-1467196451.png)
## 4、总结
我们学习Shell的正则表达式,实际的应用是什么?
* 主要是做字符串的模糊匹配,比如要求你输入一个手机号,或者身份证号,再或者是一个邮箱地址等,做模糊匹配,进行错略的过滤,来过滤掉一些不符合规则的输入。(更细的验证在后台处理,如短信或者邮箱等验证操作)
* 还有再Shell中我们也常常会读取文本中的数据,这些文本中的数据也是字符串,我们通过正则表达式来过滤出一些我们需要的数据信息。
>
> 提示:要注意区分正则表达式和通配符中的符号功能的不同。
>
>
>
* [1、正则表达式说明](#tid-3HAB8j)
* [2、基础正则表达式](#tid-SRfhNM)
* [3、练习](#tid-JX3zZz)
* [(1)准备工作](#tid-FNfDRx)
* [(2)*练习](#tid-NwGWaC)
* [(3).练习](#tid-Xwaej6)
* [(4)^和$练习](#tid-Kshb84)
* [(5)[]练习](#tid-nJnSzQ)
* [(6)[^]练习](#tid-hPWJZ6)
* [(7)\{n\}练习](#tid-Wwtcj5)
* [(8)\{n,\}练习](#tid-CxAxXh)
* [(9)\{n,m\}练习](#tid-KbCxyx)
* [4、总结](#tid-cTMGem)
\_\_EOF\_\_
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-lXqjpGsu-1654058611524)(https://blog.csdn.net/liuyuelinfighting)]繁华似锦的博客 - **本文链接:** [https://blog.csdn.net/liuyuelinfighting/p/16333656.html](https://blog.csdn.net/biggbang)
- **关于博主:** 评论和私信会在第一时间回复。或者[直接私信](https://blog.csdn.net/biggbang)我。
- **版权声明:** 本博客所有文章除特别声明外,均采用 [BY-NC-SA](https://blog.csdn.net/biggbang "BY-NC-SA") 许可协议。转载请注明出处!
- **声援博主:** 如果您觉得文章对您有帮助,可以点击文章右下角**【[推荐](javascript:void(0);)】**一下。