文章目录
显示
? 优质资源分享 ?
| 学习路线指引(点击解锁) | 知识定位 | 人群定位 |
|---|---|---|
| ? Python实战微信订餐小程序 ? | 进阶级 | 本课程是python flask+微信小程序的完美结合,从项目搭建到腾讯云部署上线,打造一个全栈订餐系统。 |
| ?Python量化交易实战? | 入门级 | 手把手带你打造一个易扩展、更安全、效率更高的量化交易系统 |
Application of deep learning methods in speech enhancement
语音增强中的深度学习应用
按:
本文是DNS,AEC,PLC等国际级语音竞赛的主办方——Microsoft Research Labs音频与声学研究组(Audio and Acoustics Research Group)于2021年发表的Sound capture and speech enhancement for speech-enabled devices中节选的一章,总结了该组今年来在语音增强领域的工作。该报告的作者为Ivan Tashev和Sebastian Braun。本篇所有图片均源自该报告及其引文。
1. (基于时频域监督学习的)语音增强模块
![998dd893ce3d4fe6685a9e435439ecf6 - [报告] Microsoft :Application of deep learning methods in speech enhancement](https://img-blog.csdnimg.cn/img_convert/998dd893ce3d4fe6685a9e435439ecf6.png "[报告] Microsoft :Application of deep learning methods in speech enhancement")
该模块主要展示了时频域语音增强的流程,包括短时傅里叶变换(STFT)、特征提取、神经网络、预测目标、增强/变换(过程)、短时傅里叶反变换(iSTFT)和损失函数几部分。其中自图中第二行开始只在训练阶段进行,本图建议与该组之前的一篇工作中的图(见下图)结合使用。![e5704f889dcf5510b8d37719eca62a02 - [报告] Microsoft :Application of deep learning methods in speech enhancement](https://img-blog.csdnimg.cn/img_convert/e5704f889dcf5510b8d37719eca62a02.png "[报告] Microsoft :Application of deep learning methods in speech enhancement")
这里主要有以下几点可以讨论:
- STFT: 由于噪声模态的多样性导致语音增强任务天然与语音分离任务有区别,利用傅里叶变换基函数将噪声和语音成分变换到特定的空间中区分模式可能更利于网络的训练和鲁棒性;此外,由于混响情况下时域算法的劣势以及阵列增强中可能的与传统波束形成技术的级联;当然还有从传统语音增强技术中发展而来的习惯;还有最最重要地,目前DNS Challenge的比赛结果。尽管有一些如demucs等优秀的基于时域的语音增强算法,基于时频域的语音增强算法可能更具优势(tips:此处为个人见解)。
- 特征提取:特征提取部分除了直接的复数谱和幅度谱,微软特别提到了对数功率谱和(幂律)压缩复数谱,在说明这两个特征之前,需要说明请注意在报告中预测目标并没有对应的对数幅度谱或者压缩复数谱,而是原始STFT域的谱或掩蔽,这点与之前网络输出与输入对应的一些文献是有区别的,其想表达的是输入经过压缩变换(不论是对数压缩还是指数压缩)的特征将有助于系统性能。
这里简要说明一下对数功率谱和(幂律)压缩复数谱,其中对数幅度谱的使用见于该组的这篇和这篇,定义为P=log10(|X(k,n)|2)P=log10(|X(k,n)|2)P = log10(|X(k, n)|^2)MARKDOWN_HASHae44d570527972ff741dcc51c6a36669MARKDOWNHASH;
而幂律压缩复数谱可参考这篇,定义为Xcprs=X(k,n)|X(k,n)||X(k,n)|cXcprs=X(k,n)|X(k,n)||X(k,n)|cX\{cprs}=\frac{X(k,n)}{|X(k,n)|}|X(k,n)|^{c}x_mag = torch.norm(x_stft, dim=-1) + 1e-9 x_cprs_mag = x_mag ** c x_cprs = torch.stack((x_stft[..., 0] / x_mag * x_cprs_mag, x_stft[..., 1] / x_mag * x_cprs_mag), dim=-1)
* 损失函数:报告中推荐的是压缩谱损失,其他损失包括mask的距离、能量损失(SDR/SI-SDR)、谱距离、感知加权损失和(以上几项或以上几项和其他项的)联合损失。
损失函数分别定义和测评在[文献](https://blog.csdn.net/biggbang)和[文献](https://blog.csdn.net/biggbang)中,其中一部分见下图
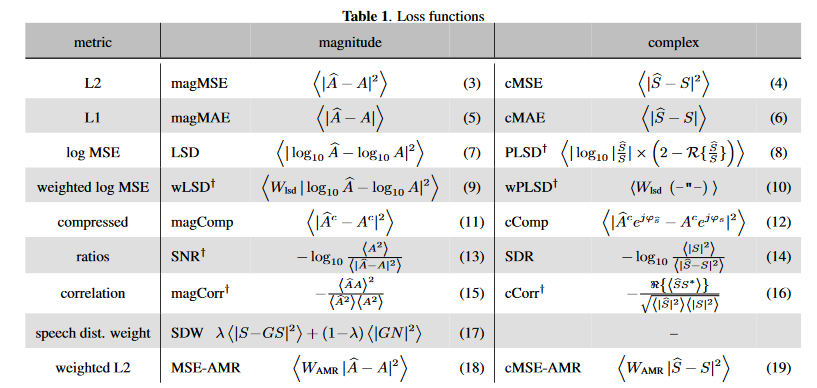
推测压缩谱损失推荐的是幅度正则的压缩谱损失(Magnitude-regularized compressed spectral loss):L=1σcS(λ∑k,n|Sc−Sˆc|2+(1−λ∑k,n||S|c−|Sˆ|c|2))L=1σSc(λ∑k,n|Sc−S^c|2+(1−λ∑k,n||S|c−|S^|c|2))\mathcal{L}=\frac{1}{\sigma\_S^{c}}(\lambda\sum\_{k,n}{|S^c-\widehat{S}^c|^2+(1-\lambda\sum\_{k,n}{||S|^c-|\widehat{S}|^c|^2})}),其中σSσS\sigma\_S是纯净语音有声段的能量,压缩谱的操作与上文定义一致,ccc和λλ\lambda微软推荐都为0.3。
## 2. 训练数据的生成与增广
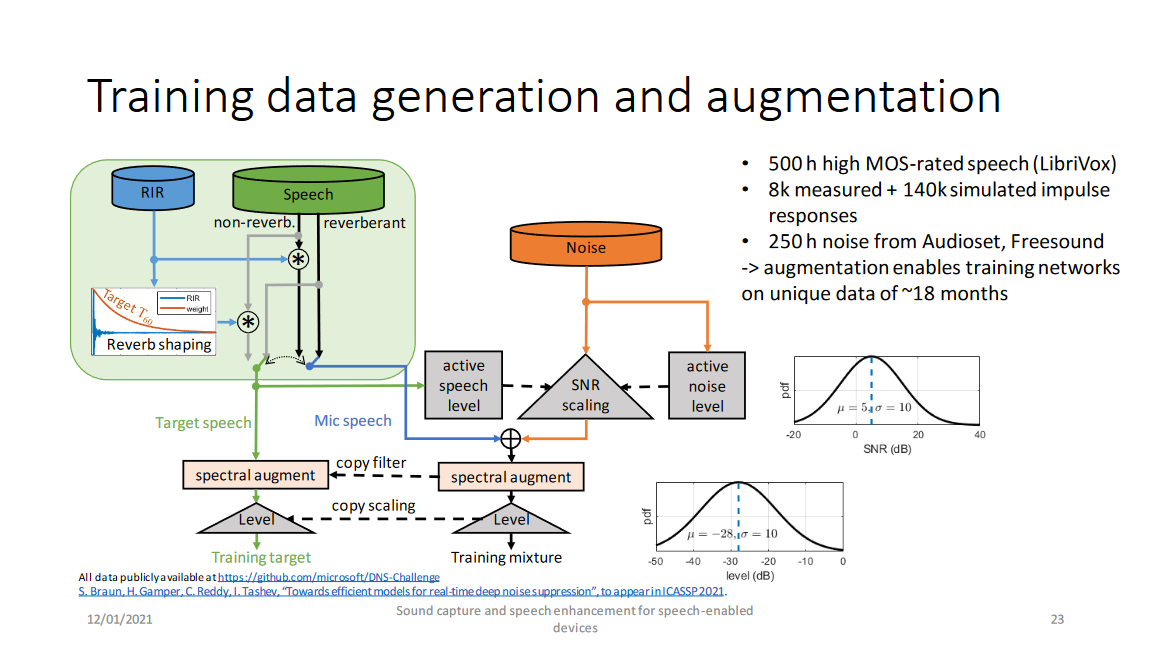
微软推荐的数据生成方式如上图,先不考虑混响情况,纯净语音和噪声分别计算其能量,根据信噪比混合得到带噪数据,而后用相同的滤波器进行谱增广,最后调节语音音量的动态范围。需要注意的是:
* 纯净语音要进行清洗,选择MOS高的,排除“脏”数据
* 每条预料要足够长(微软推荐10s一句,根据其测评在其模型、特征和loss下至少应长于5s,当条件改变句子最短长度也可能变化)
* 该报告推荐的信噪比按均值5 dB,方差10 dB的高斯分布随机选取
* 该报告推荐的dBFS音量增广按均值-28 dB,方差10 dB的高斯分布随机选取
* 谱增广是指RNNoise中使用的滤波器:H(z)=1+r1z−1+r2z−21+r3z−1+r4z−2H(z)=1+r1z−1+r2z−21+r3z−1+r4z−2H(z)=\frac{1+r\_1z^{-1}+r\_2z^{-2}}{1+r\_3z^{-1}+r\_4z^{-2}},其中ri∼U(−38,38)ri∼U(−38,38)r\_i\sim\mathcal{U}(-\frac{3}{8},\frac{3}{8})。但是该报告引用文献中指出由于数据量重足,谱增广是不必要的
最后考虑混响情况(图中绿色区域):和其他文章一样,房间冲激响应(RIR)卷积纯净语音得到混响语音。而为了使语音听起来自然,目标语音仍带少量混响,具体的实现上是令语音与经加权函数加权的RIR卷积,其中加权函数的定位为:wRIR(t)=exp(−(t−t0)6log(10)0.3),ift≥t0,(otherwisewRIR(t)=1)wRIR(t)=exp(−(t−t0)6log(10)0.3),ift≥t0,(otherwisewRIR(t)=1)w\_{RIR}(t)=exp(-(t-t\_0)\frac{6log(10)}{0.3}), if\quad t \ge t\_0,(otherwise\quad w\_{RIR}(t)=1)
## 3. 有效的网络架构
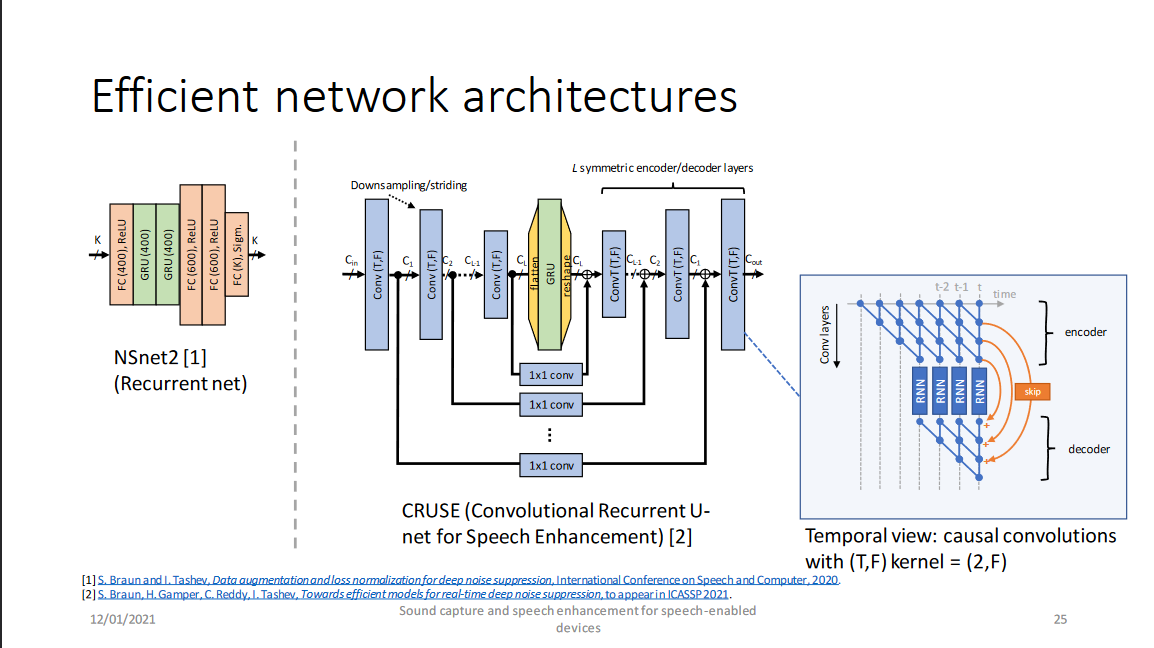
微软提供了两个网络架构,分别为[NSNet2](https://blog.csdn.net/biggbang)(DNS Challenge的baseline)和[CRUSE](https://blog.csdn.net/biggbang)(DNS Challenge中微软提交的比赛方案Microsoft-2)。
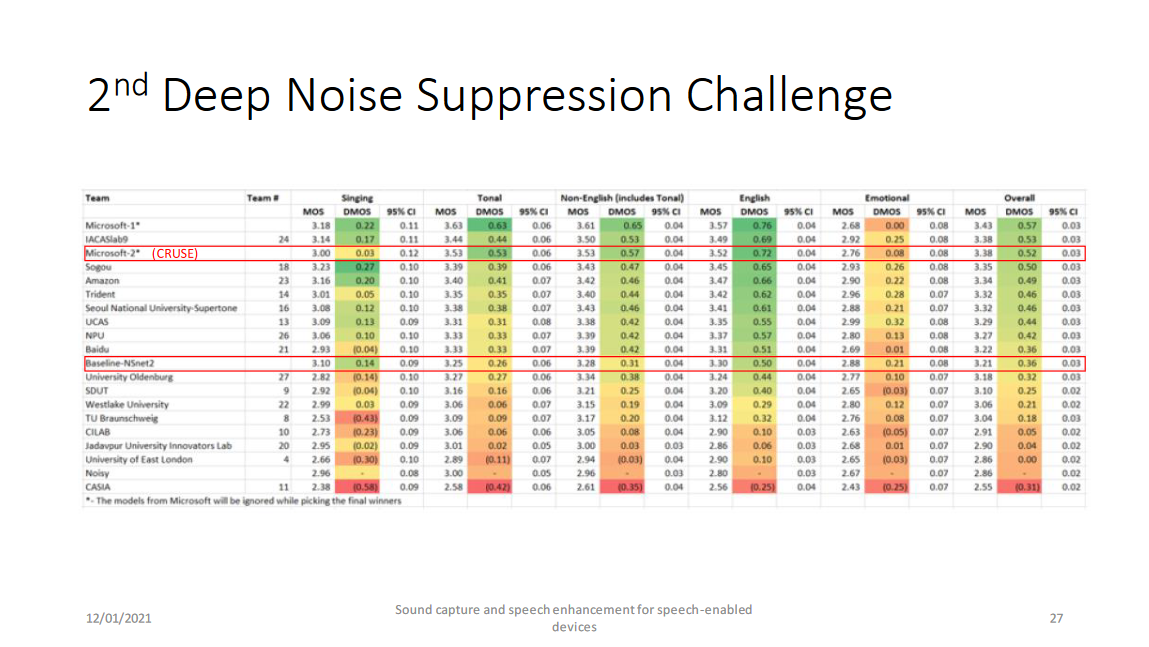
以上两个网络分别是RNNoise(by Valin)-style的幅度谱域模型和GCRN(by Tan)-style的复数谱域模型,RNNoise和GCRN将在之后的博客中将进行详细介绍,这两个网络的介绍请参见[博客](https://blog.csdn.net/biggbang)和[博客](https://blog.csdn.net/biggbang)中介绍。最后是他们的结果:
转载请注明:xuhss » [报告] Microsoft :Application of deep learning methods in speech enhancement