Python微信订餐小程序课程视频
https://blog.csdn.net/m0_56069948/article/details/122285951
Python实战量化交易理财系统
https://blog.csdn.net/m0_56069948/article/details/122285941
Fauce:Fast and Accurate Deep Ensembles with Uncertainty for Cardinality Estimation 论文解读(VLDB 2021)
- 本篇博客是对Fauce:Fast and Accurate Deep Ensembles with Uncertainty for Cardinality Estimation 论文的解读。原文链接为p1950-liu.pdf (vldb.org)
- 本文设计一种基于集成深度神经网络的基于查询的选择度估计器,文章的主要贡献有:
- 第一次设计实现了一种可以反映估计结果的不确定性的技术估计器。
- 介绍了一种新的查询特征化的方法,利用了数据库的连接模式捕获表列间的真是相关性。
- 在数学上定义了估计不确定性的含义,并通过设计实现集成深度神经网络实现了对估计结果的不确定性的评估。
- 通过不确定性管理模块可以通过增量学习进一步提高模型的准确性。
转化为回归问题
因为查询的基数均为实数,因此我们可以建立一个回归模型MMM。对于任意范围的查询语句,模型MMM可以产生匹配或接近实际基数值的回归结果。
模型MMM作为一个回归模型,其输入应为一个实值向量。因此我们必须将给定的查询语句转化为一个对应的实值向量,这个过程称为查询特征化。本文的查询特征化方法将在后文介绍。总之MMM将特征化向量作为模型的输入,实际的基数值作为标签进行训练以期望产生一个可以很好拟合query-cardinality映射关系的函数。
查询特征化
在训练MMM预测基数前,我们必须将查询语句转换成满足模型输入形式的实值向量。一个SQL查询语句可以表示成
Tables encoding
- 本文不同于其他方法中的one-hot或二进制编码而是使用图嵌入的方法对数据库表进行编码。我们将数据库的连接模式看做无向图,其中顶点是表,每条边连接两个可以相连的表。我们将数据库连接模式图作为某种图嵌入方法的输入,输出为每个顶点的嵌入编码,每个输出的向量都是对应表的编码。若查询中不涉及表,我们就用0向量来代替。与二进制编码类似,我们将图嵌入的长度固定为logm+1logm+1log^{m+1}维,其中m表示数据库中表的个数。
")
Joins encoding
1.找出所有可能的连接图
2.对所有的连接图做嵌入处理
下面介绍Joins encoding算法:
* 总体流程:

* 给定一个根节点t,连接图深度d,寻找满足条件的连接图:

* 首先根据连接模式找出所有的连接图。(Algothm 1-4;Algothm 2)其次为每个连接图寻找上下文信息,本文中认为一个根节点为ttt长度为ddd 的连接图的context为以ttt的邻居节点为根节点,长度为 {d−1,d,d+1}{d−1,d,d+1}\{d-1,d,d+1\} 的连接图。(Algothm 11-14)接着利用上下文信息对每个连接图进行编码,具体思想类似词嵌入和图嵌入,利用当前的连接图试图去预测其上下文中的连接图。将隐藏层的结果当做embedding。(Algothm1 15-17)
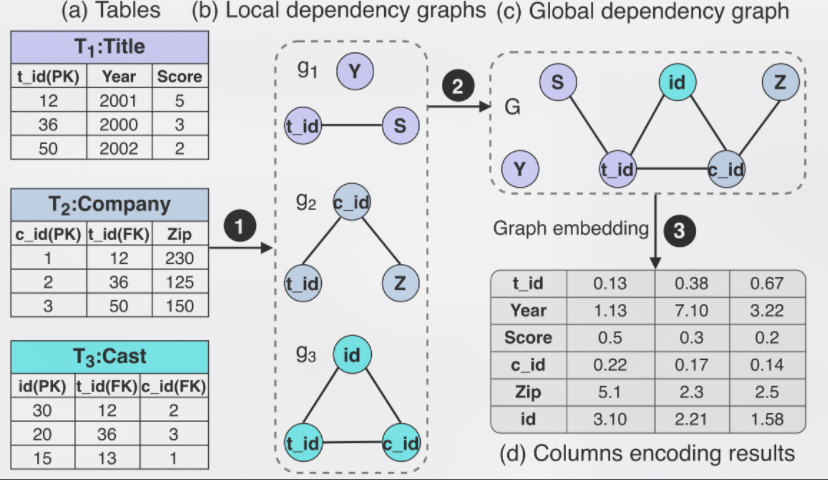
### Columns encoding
列之间的相关性关系可以作为一种有用的信息应用于列编码中。本文利用图嵌入针对数据库不同列之间的真实相关性对每一列进行编码。该编码方法分为三步:
1.构造单表内关系依赖图
2.构造全局关系依赖图
3.根据全局关系依赖图进行图嵌入
我们通过计算随机相关系数(RDC)和一个阈值ttt来判断不同列之间是否存在依赖关系。
### Values encoding
* 在一个有共有n列的数据库中,所有的连接查询语句的过滤子句的条件都可以表示为
(lb11≤Col11≤ub11)∩...∩(lbcmm≤Colcmm≤ubcmm)(lb11≤Col11≤ub11)∩...∩(lbmcm≤Colmcm≤ubmcm)({lb}\_1^1\leq {Col}\_1^1\leq{ub}\_1^1)\cap{...}\cap({lb}\_m^{cm}\leq {Col}\_m^{cm}\leq{ub}\_m^{cm}) 的形式,其中 ColjiColij{Col}\_i^{j} 表示数据库中第iii个表的第jjj列属性,lbjilbijlb\_i^j 和 ubjiubijub\_i^j 分别是查询中的 ColjiColij{Col}\_i^{j} 值的上限和下限。我们将表 TiTiTi的第j列属性的值域表示为[minji,maxji][minij,maxij][min\_i^j,max\_i^j] ,如果查询中没有对某一列进行约束,我们就用它的值域范围表示。
* 举个例子:一个数据库有两个列属性 ColjiColijCol\_i^j 和 ColnmColmnCol\_m^n 且它们的值域均为 (0,100)(0,100)(0,100),有一个查询的过滤条件为 (20≤Colji≤50)(20≤Colij≤50)(20\leq Col\_i^j\leq 50),我们就可以将这个查询语句的过滤条件表示为 (20≤Colji≤50)∩(0≤Colji≤100)(20≤Colij≤50)∩(0≤Colij≤100)(20\leq Col\_i^j\leq 50)\cap (0\leq Col\_i^j\leq 100).
* 假设一个数据库存在 CMCMCM 列属性,我们就可以用 CMCMCM 对 (lb,ub)(lb,ub)(lb,ub) 来表示一个查询语句的过滤子句,即我们可以用 2CM2CM2CM 维的向量对过滤子句进行编码。
综上,我们完成了对
## 训练数据处理
### 基数变换
模型 MMM 的训练数据为大量的
* log Transformation:利用取对操作可以缓解数据分布倾斜的情况。
* min-max scaling : 对标签进行放缩操作,使之分布在 (0,1)(0,1)(0,1)区间内,可以避免标签差距过大影响训练过程。card′=card−min\_cardmax\_card−min\_cardcard′=card−min\_cardmax\_card−min\_cardcard'= \frac{card-min\\_card}{max\\_card-min\\_card}
### 训练数据生成
* 由于查询的基数分布很容易发生偏差,因此从所有查询的空间进行简单采样可能会产生不均匀的训练数据集和次优的基数估计值。为了生成统一的训练数据集,我们基于以下两种规则生成训练数据:
+ 通用性:查询应该来自从数据库连接模式中派生出的多种连接图。
+ 多样性:查询的训练数据在过滤属性和基数上应该是不同的。
* 基于以上两种规则,我们可以通过以下方式生成训练数据:我们将查询语句均匀的划分到每个不同的连接图。(通用性)为了生成对连接图的查询,我们先从连接图内部随机采样出一个元组并获得该元组的非空列数记为 NNN,接着我们从(1,N)(1,N)(1,N)中随机的选择一个过滤谓词个数 npnpnp 接着我们随机抽取np个列并根据其支持的运算符生成过滤条件。(多样性)
## 模型的选择
* 我们使用深层神经网络的集合(DNN Ensembles)来估计基数。选择DNN,因为查询的分布非常复杂,DNN是强大的模型,在许多任务中都取得了令人印象深刻的准确性。此外,之前的工作已经显示了使用系综技术提高基数估计的优势。
* Ensembles。Deep ensembles是一种学习范式,其中为同一任务训练有限数量的DNN集合。一般来说,深度集合的构建分为两步:
(1)在没有任何交互的情况下并行训练多个DNN;
(2)计算每个DNN的估计结果的加权平均值,作为深度集合的最终输出
## 量化不确定性
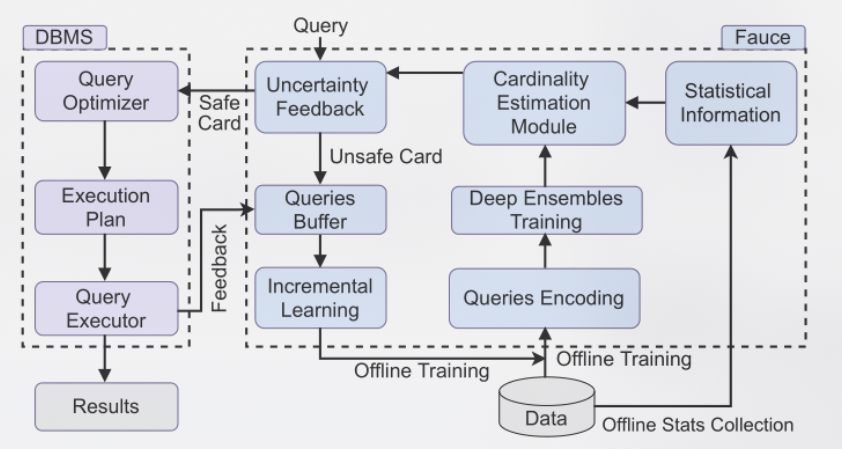
* 在数据库中使用基数估计是基于一个默认的假设,即估计的结果是安全的。然而这种假设并不是有效的。若是估计器产出了一个错误的基数估计值传递给优化器,就会生成一个错误的执行计划。为了解决这个问题,一种更好的方案是基数估计模型同时生成基数估计结果和相应的不确定程度来度量这个基数估计是否可信。基于不确定性,DBMS可以评估是否可以相信这个估计结果并将其用于查询计划生成中。
* 在该文中,我们运用的是集成的深度神经网络进行训练就是为了能够量化估计的不确定性。注意这里的集成指的并不是神经网络的深度,而是指一系列独立的神经网络。我们训练了很多个相同的网络,虽然它们的训练集都一样但是因为深度神经网络的独特结构,其内部权重肯定有所不同。在推理阶段,我们根据这一系列神经网络的输出的方差来衡量不确定性。思路类似于随机森林。当方差很小时,证明大家都认为基数是这么多,我们可以认为此时估计结果可以信任,当方差过大时,证明大家分歧很大,此时基数估计的结果不是很可信。
* 在本文中,我们有两种模型的输出,一是在进行查询特征化时,输入一个query语句要得到对应的特征化向量;二是在进行基数估计时,输入一个查询特征化向量输出一个基数估计的值。因此这里将不确定性分为两种:数据不确定性和模型不确定性。分别定量为查询特征化输出的方差和基数估计输出的方差。
* 在处理不确定性时,我们给两种不确定性设定两个阈值,认为超过这个阈值就不可信。这样我们可以得到四种情况:
+ 数据可信,模型可信
+ 数据不可信,模型可信
+ 数据可信,模型不可信
+ 数据不可信,模型不可信
又因为我们的任务只关注基数估计的结果,所以当模型可信时我们就可认为结果可信。因此实际只有三种情况:
+ 模型可信:接受估计结果。
+ 数据可信,模型不可信:我们将query存入缓冲区,在DBMS中返回真实的cardinaliy并进行增量训练。
+ 数据不可信,模型不可信:除了要讲query存入缓冲区后续进行增量训练外,在训练数据生成阶段扩大训练数据规模。

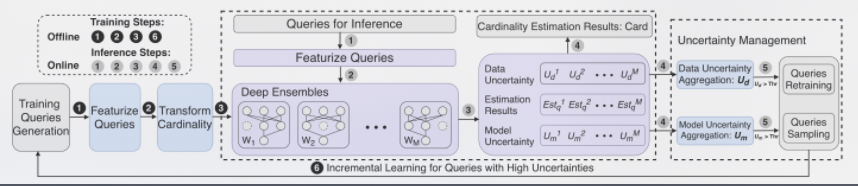
## Work Flow
---
---
---
---
---
---
觉得有帮助的话给笔者点个赞吧!欢迎评论区互相交流!O(∩\_∩)O
转载请注明:xuhss » Fauce:Fast and Accurate Deep Ensembles with Uncertainty for Cardinality Estimation 论文解读(VLDB 2021)